softmax with CUDA worklog - pt II (Block Reduction to Tiled Online Softmax)
I spent the last couple days trying to make sense of the online softmax implementation by the original authors.
The online softmax implementation was pretty intuitive once i understood the math, but the top k took a while to wrap my head around. but before we get to that, let's execute t he block reduction left over from the last time.
I'll extend my base code to incorporate the things we study here and see how it affects performance. The goal remains the same. Beat triton's kernel.
so this is where we were at last time.
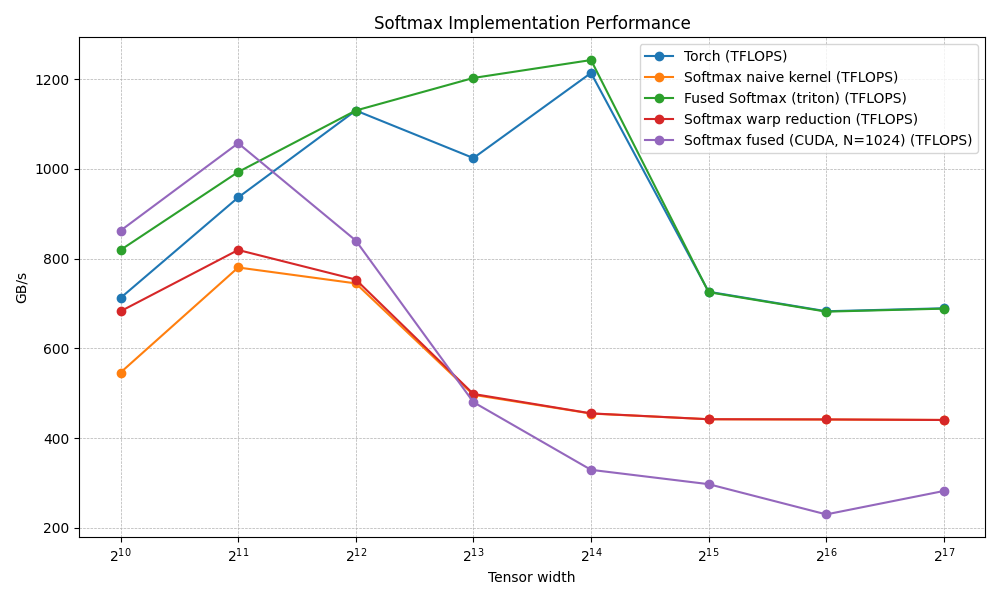
since then I've also found that the OG Mr. Dao has been contributing to this repo here so i want to check against that as well. in that way I'll end up touching on cuteDSL.
So the things to touch on in this one are:
Block Fused
from the previous post's warp fused kernel where we load a warp per row:
chunks in row = N / 4
threads = 32
chunks per thread = (N/4) / 32 = N / 128
floats per thread = chunks × 4 = N / 32
essentially N/32 is the important factor here
At N = 4096:
chunks per thread = 4096 / 128 = 32 float4s
floats per thread = 32 × 4 = 128 floats ← in registers
128 registers just for buf[]. A GPU thread has ~255 total. Add loop indices, local_max, local_sum, invSum, pointer arithmetic we're over the edge. The compiler spills buf to local memory (L1/L2 backed). Every register access is now a cache load.
but if we load a whole block into a row we see that within the same row, more threads split the work:
chunks in row = N / 4
threads = 1024
chunks per thread = (N/4) / 1024 = N / 4096
floats per thread = chunks × 4 = N / 1024
At N = 65536:
chunks per thread = 65536 / 4096 = 16 float4s
floats per thread = 16 × 4 = 64 floats ← comfortable
64 registers for buf[], ~190 remaining for everything else. No spill. The row still lives entirely in registers.
The scaling relationship
floats per thread = N / threads
To avoid spill, we need floats per thread < ~180 (leaving headroom):
| N | 32 threads (warp) | 1024 threads (block) |
|---|---|---|
| 1024 | 32 ✓ | 1 ✓ |
| 4096 | 128 ← edge | 4 ✓ |
| 8192 | 256 ✗ spills | 8 ✓ |
| 65536 | 2048 ✗ | 64 ✓ |
| 262144 | — | 256 ✗ spills |
The block kernel doesn't remove the register constraint — it just divides N by 1024 instead of 32, pushing the spill boundary 32× higher. That's the entire trick
for the sake of keeping syncronicity with the previous part I'll still use t he A100, but i so dont want to. This block fusion would blow right past triton if I used a H100 cuz it's max threads per SM is 2048 and this kernel would demolish triton there, but can't be messing with the process just to boost my own numbers. we're not politicians here.
the core of the algo is this:
template <int N>
__global__ __launch_bounds__(FUSED_BLOCK_SIZE) void softmax_fused_block_kernel(
const float *__restrict__ in, float *__restrict__ out, int M) {
constexpr int NP = N / (FUSED_BLOCK_SIZE * 4); // float4s per thread
constexpr int n_warps = FUSED_BLOCK_SIZE / WARP_SIZE;
extern __shared__ float smem[];
float *smem_max = smem;
float *smem_sum = smem + n_warps;
const int tid = threadIdx.x;
const int row = blockIdx.x;
if (row >= M)
return;
const float4 *row_in = reinterpret_cast<const float4 *>(in + row * N);
float4 *row_out = reinterpret_cast<float4 *>(out + row * N);
float4 buf[NP];
float local_max = -INFINITY;
// 1. for all packs
// read vram once
// - Load row into registers
// - compute local max
// sync max reduce across the block
#pragma unroll
for (int i = 0; i < NP; i++) {
buf[i] = row_in[tid + i * FUSED_BLOCK_SIZE];
local_max = fmaxf(
local_max, fmaxf(fmaxf(buf[i].x, buf[i].y), fmaxf(buf[i].z, buf[i].w)));
}
float row_max = blockReduceMax(local_max, smem_max); // reduce across all 32 warps inside the 1024 block size and provide final row max
// 2. [register] all packs
// - exp on register data
// - accumulate local sum
// sync reduce across block and multiply by reciprocal
float local_sum = 0.0f;
#pragma unroll
for (int i = 0; i < NP; i++) {
buf[i].x = __expf(buf[i].x - row_max);
buf[i].y = __expf(buf[i].y - row_max);
buf[i].z = __expf(buf[i].z - row_max);
buf[i].w = __expf(buf[i].w - row_max);
local_sum += buf[i].x + buf[i].y + buf[i].z + buf[i].w;
}
float invSum = __frcp_rn(blockReduceSum(local_sum, smem_sum));
// we use the in-build compute 1/x func
// https://cseweb.ucsd.edu//classes/wi15/cse262-a/static/cuda-5.5-doc/html/cuda-math-api/group__CUDA__MATH__INTRINSIC__SINGLE.html#group__CUDA__MATH__INTRINSIC__SINGLE_1gba455801af8ac9af405a5d37ef2f077b
// this prevents us from doing division computation 4 times in the next step
// 3. Normalize register data, write back
#pragma unroll
for (int i = 0; i < NP; i++) {
buf[i].x *= invSum;
buf[i].y *= invSum;
buf[i].z *= invSum;
buf[i].w *= invSum;
row_out[tid + i * FUSED_BLOCK_SIZE] = buf[i];
}
}we start to get pretty good performance from this kernel
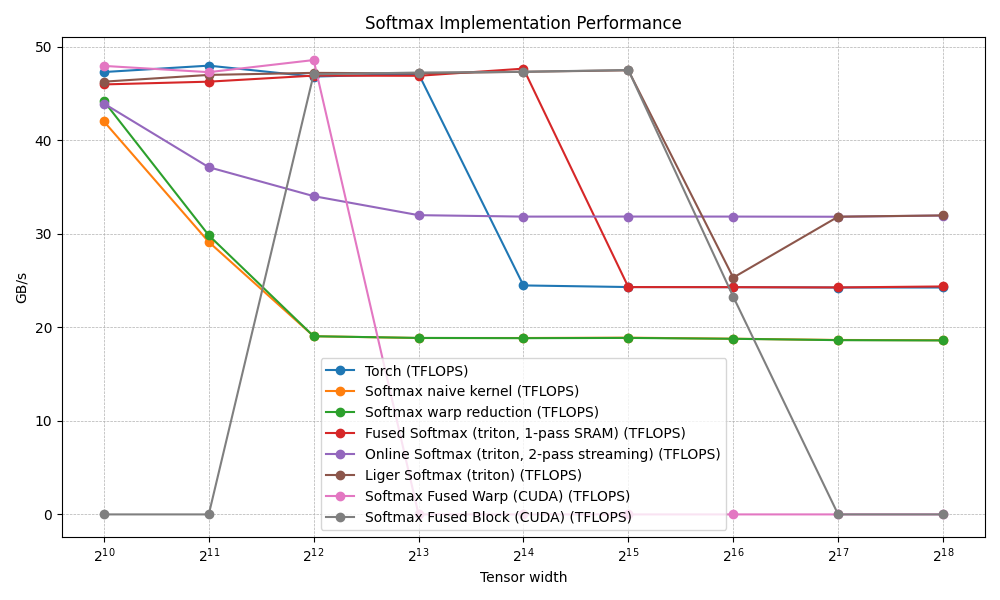
we matches triton's fused kernel until N of size 16384, have considerably better performance at 32k. but after that the toll of this 3 pass starts to creep in.
the memory fetches are optimal at 2N (1 read + 1 write). but we face the same problem as before just a factor of 32 later that the register is spilling beyond 65k
register usage can be scaled like this:
N NP buf regs total ~regs spill under maxrregcount=64?
───────────────────────────────────────────────────────────────────
4096 1 4 18 no
8192 2 8 22 no
16384 4 16 30 no
32768 8 32 46 no
65536 16 64 78 YES under maxrregcount=64
Occupancy at N=65536 (NP=16, ~78 regs/thread):
78 regs × 1024 threads = 79872 regs/block
SM register file: 65536 regs (Turing/Ampere)
65536 / 79872 = 0.82 → 1 block/SM (HW rounds down) = 50% occupancy
a note on __expf()
__expf() uses the SFU (Special Function Unit), a dedicated piece of silicon on each SM that computes transcendentals (exp, log, sin, rcp, rsqrt) in ~8 cycles.
read more here: intrinsic funcs
this is where the elegantly simple solution of online softmax comes into the picture.
Online Softmax
sometimes you come across an idea and you think, duh, I could've come up with that. that's how simple it looks.
I mean yeah, of course, just store the local max and the local sum from the previous state locally and then use that for the new computation, why save the whole row?? most algos do this in regular programming, right?
You think this. but obviously you need genius intuition to solve it, but it's always nice to think such things.
anyways, here's the code:
// Implementation from
// https://arxiv.org/abs/1805.02867
// https://github.com/NVIDIA/online-softmax?tab=readme-ov-file
// Merge two partial online-softmax accumulators
__device__ __forceinline__ void onlineMerge(float &m1, float &s1, float m2,
float s2) {
float M = fmaxf(m1, m2);
s1 = s1 * __expf(m1 - M) + s2 * __expf(m2 - M);
m1 = M;
}
// Warp-level online reduction via butterfly shuffle
__device__ __forceinline__ void warpReduceOnline(float &max_val,
float &sum_val) {
// CG: named warp tile communicates intent and manages the active mask
auto warp = cg::tiled_partition<32>(cg::this_thread_block());
#pragma unroll
for (int mask = WARP_SIZE / 2; mask > 0; mask >>= 1) {
// float other_max = __shfl_xor_sync(0xffffffff, max_val, mask);
// float other_sum = __shfl_xor_sync(0xffffffff, sum_val, mask);
float other_max = warp.shfl_xor(max_val, mask);
float other_sum = warp.shfl_xor(sum_val, mask);
// note: using cg doesn't really do anything for the performance. it's just a good deterministic way for the threads to communicate
onlineMerge(max_val, sum_val, other_max, other_sum);
}
}
template <int BS>
__device__ __forceinline__ void
blockReduceOnline(float &max_val, float &sum_val, float *scratch_max,
float *scratch_sum) {
constexpr int n_warps = BS / WARP_SIZE;
const int lane = threadIdx.x % WARP_SIZE;
const int wid = threadIdx.x / WARP_SIZE;
auto block = cg::this_thread_block();
warpReduceOnline(max_val, sum_val); // intra-warp, register-only
if (lane == 0) {
scratch_max[wid] = max_val; // n_warps writes
scratch_sum[wid] = sum_val;
}
// __syncthreads();
block.sync();
if (threadIdx.x < n_warps) {
max_val = scratch_max[threadIdx.x];
sum_val = scratch_sum[threadIdx.x];
} else {
max_val = -INFINITY;
sum_val = 0.0f;
}
if (wid == 0)
warpReduceOnline(max_val, sum_val);
if (threadIdx.x == 0) {
scratch_max[0] = max_val;
scratch_sum[0] = sum_val;
}
// __syncthreads();
block.sync();
max_val = scratch_max[0];
sum_val = scratch_sum[0];
}
// Template on NP (float4s per thread) and BS (block size).
// BS varies so small N (1024, 2048) can be served without a 1024-thread block
// that would have NP=0 and spill everything.
template <int NP, int BS>
__global__ __launch_bounds__(BS) void softmax_online_kernel(
const float *__restrict__ in, float *__restrict__ out, int M) {
constexpr int N =
NP * BS * 4; // recovered at compile time for pointer arithmetic
constexpr int n_warps = BS / WARP_SIZE;
extern __shared__ float smem[];
float *smem_max = smem;
float *smem_sum = smem + n_warps;
const int tid = threadIdx.x;
const int row = blockIdx.x;
if (row >= M)
return;
const float4 *row_in = reinterpret_cast<const float4 *>(in + row * N);
float4 *row_out = reinterpret_cast<float4 *>(out + row * N);
float4 buf[NP];
float local_max = -INFINITY;
float local_sum = 0.0f;
#pragma unroll
for (int i = 0; i < NP; i++) {
buf[i] = row_in[tid + i * BS];
float vals[4] = {buf[i].x, buf[i].y, buf[i].z, buf[i].w};
#pragma unroll
for (int j = 0; j < 4; j++) {
float new_max = fmaxf(local_max, vals[j]);
local_sum =
local_sum * __expf(local_max - new_max) + __expf(vals[j] - new_max);
local_max = new_max;
}
}
// Single combined reduction: (max, sum) reduced together → 2 syncs total
blockReduceOnline<BS>(local_max, local_sum, smem_max, smem_sum);
float row_max = local_max;
float invSum = __frcp_rn(local_sum);
// Phase 2: Normalize + write back
#pragma unroll
for (int i = 0; i < NP; i++) {
buf[i].x = __expf(buf[i].x - row_max) * invSum;
buf[i].y = __expf(buf[i].y - row_max) * invSum;
buf[i].z = __expf(buf[i].z - row_max) * invSum;
buf[i].w = __expf(buf[i].w - row_max) * invSum;
row_out[tid + i * BS] = buf[i];
}
}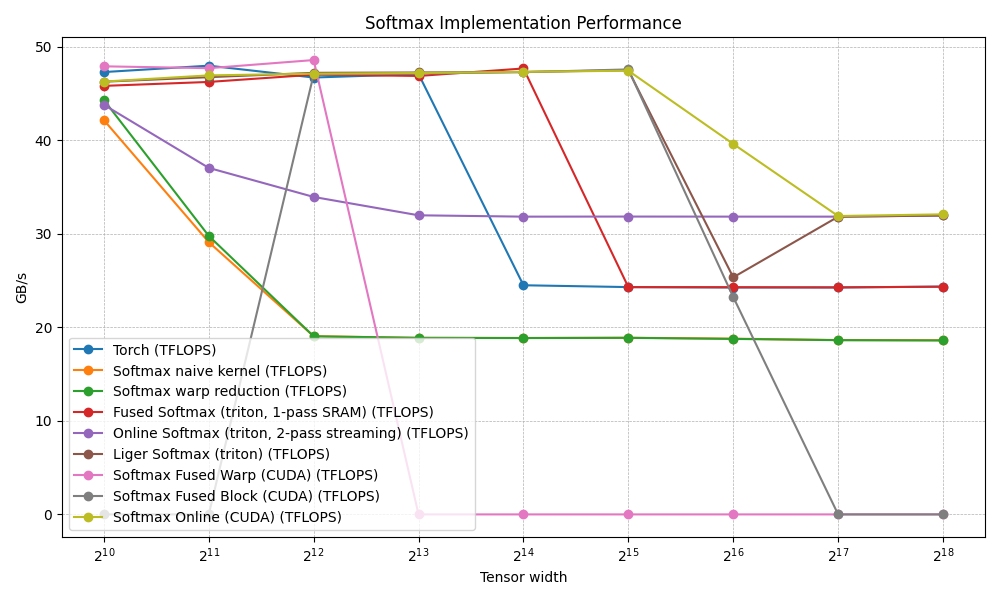
we've prevented that 65k dip we saw last time with the fusedBlock.
the idea is very simple first pass:
- load into buf[np] registers
- accumulate online while loading into the registers
- block reduce and save row_max and row_sum in the smem
second pass
- compute expf(buf[i]-row_max)*invSum and write back to dram
but this should cause spill too right?
yeah, but we did a little trick
I created another kernel for 131072 and up N size which is:
template <int NP, int BS>
__global__ __launch_bounds__(BS) void softmax_online_2pass_kernel(
const float *__restrict__ in, float *__restrict__ out, int M) {
constexpr int N = NP * BS * 4;
constexpr int n_warps = BS / WARP_SIZE;
extern __shared__ float smem[];
float *smem_max = smem;
float *smem_sum = smem + n_warps;
const int tid = threadIdx.x;
const int row = blockIdx.x;
if (row >= M) return;
const float4 *row_in = reinterpret_cast<const float4 *>(in + row * N);
float4 *row_out = reinterpret_cast<float4 *>(out + row * N);
// Pass 1: accumulate (max, sum) — no buf[], O(1) register footprint
float local_max = -INFINITY, local_sum = 0.0f;
#pragma unroll
for (int i = 0; i < NP; i++) {
float4 v = row_in[tid + i * BS];
float vs[4] = {v.x, v.y, v.z, v.w};
#pragma unroll
for (int j = 0; j < 4; j++) {
float new_max = fmaxf(local_max, vs[j]);
local_sum = local_sum * __expf(local_max - new_max) + __expf(vs[j] - new_max);
local_max = new_max;
}
}
blockReduceOnline<BS>(local_max, local_sum, smem_max, smem_sum);
const float row_max = local_max;
const float invSum = __frcp_rn(local_sum);
// Pass 2: reload via __ldg (read-only cache) → exp-normalize → write
#pragma unroll
for (int i = 0; i < NP; i++) {
float4 v = __ldg(row_in + tid + i * BS);
v.x = __expf(v.x - row_max) * invSum;
v.y = __expf(v.y - row_max) * invSum;
v.z = __expf(v.z - row_max) * invSum;
v.w = __expf(v.w - row_max) * invSum;
row_out[tid + i * BS] = v;
}
}When registers spill, the compiler inserts hidden LDG/STG (load/store global) instructions to save/restore registers to "local memory" which is physically DRAM. Each spilled float4 = 16 bytes extra read + 16 bytes extra write. At NP=32 with heavy spilling, true memory traffic can reach 4-5N instead of the target 2N. the only way to prevent register spill is to either tile or get rid of the register.
I chose the more destructive option
so getting rid of the register for larger Ns we do
first pass
- stream data (float4 loaded and discarded) and online accumulate
- block reduce and get (rowMax, invSum)
second pass
- reload data using __ldg as it routes through read-only / L1 cache essentially we've seen this data in the prior read, so instead of pulling from the dram, we pull from the recent cache, and our gpu provides the func for that.
On forther research I found that whether __ldg() it hits L1 depends on the row size vs L1 capacity (~192 KB). For N=131072, one row = 512 KB >> L1 → L2 hit likely; for M=2048 rows, total = 1 GB >> L2 → most __ldg reloads go to HBM.
it increases the total cost by 1N more reads as well, but protects the register from spilling. this slight hack help us bypass ligers performance for 1 singular N size, and if I'm able to beat all the people building liger, even for 1 size. I'm a happy man.
is this cheating... hmmmmm
hmmmmmmmmmm
hmmmmmmmmmmmmmmm
Online softmax v2
since we've come this far, why not try to see if we can beat triton's implementation for online softmax for the larger tensor size. is what i thought when i tried to write this.
I promise this is the last kernel I'll add here.
like a child excited.. let me first show you what this kernel does 😁
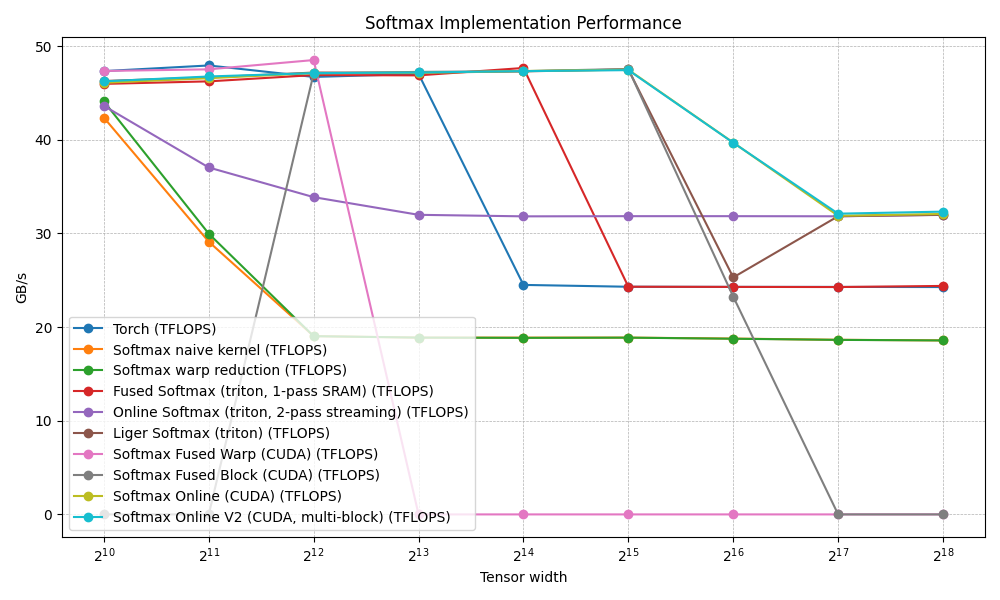
if you noticed a pattern is how we optimized the warp fused to the block fused, you'll understand how this one works.
the point is to improve NP. which ios the number of packs of floats being processed. in fused warp we had np = N / (32 * 4) in block we got to down to N / (1024 * 4). a 32x reduction and equivalently we were able to prevent register spilling and get a bit better performance
so similarly, in the online procedure above, a whoel row is owned by a block -> np = N / (block * 4)
we don't like this. if we broke the whole row up into smaller splits, we could get a better np per block by splitting the row np = (N/splits) / (blocks * 4)
so previously we had at N = 262144, np = 262144 / (1024 * 4) = 64
now if we, let's say, want 8 splits, then np_per_block = (262144 / 8) / (1024 * 4) = 8
8 * 4 = 32 data register + ~16 overhead ~= 48 registers/thread
very comfortable
we finally have a kernel that stays stable for the larger N sizes. pretyt neat. here's the cods for this:
// get max and sum per tile
template <int NP, int BS>
__global__ __launch_bounds__(BS) void softmax_v2_stats_kernel(
const float *__restrict__ in, float *__restrict__ partial_max,
float *__restrict__ partial_sum, int M, int N, int splits) {
constexpr int n_warps = BS / WARP_SIZE;
const int chunk_f4 = NP * BS;
extern __shared__ float smem[];
float *smem_max = smem;
float *smem_sum = smem + n_warps;
const int tid = threadIdx.x;
const int row = blockIdx.x / splits;
const int split_id = blockIdx.x % splits;
if (row >= M)
return;
const int f4_offset = split_id * chunk_f4;
const float4 *chunk_in =
reinterpret_cast<const float4 *>(in + row * N) + f4_offset;
float local_max = -INFINITY;
float local_sum = 0.0f;
#pragma unroll
for (int i = 0; i < NP; i++) {
float4 v = chunk_in[tid + i * BS];
float vals[4] = {v.x, v.y, v.z, v.w};
#pragma unroll
for (int j = 0; j < 4; j++) {
float new_max = fmaxf(local_max, vals[j]);
local_sum =
local_sum * __expf(local_max - new_max) + __expf(vals[j] - new_max);
local_max = new_max;
}
}
blockReduceOnlineV2<BS>(local_max, local_sum, smem_max, smem_sum);
if (threadIdx.x == 0) {
int idx = row * splits + split_id;
partial_max[idx] = local_max;
partial_sum[idx] = local_sum;
}
}
template <int NP, int BS>
__global__ __launch_bounds__(BS) void softmax_v2_normalize_kernel(
const float *__restrict__ in, float *__restrict__ out,
const float *__restrict__ partial_max,
const float *__restrict__ partial_sum, int M, int N, int splits) {
const int row = blockIdx.x / splits;
const int split_id = blockIdx.x % splits;
if (row >= M)
return;
const int tid = threadIdx.x;
float global_max = -INFINITY;
float global_sum = 0.0f;
for (int s = 0; s < splits; s++) {
int idx = row * splits + s;
onlineMergeV2(global_max, global_sum, partial_max[idx], partial_sum[idx]);
}
float invSum = __frcp_rn(global_sum);
const int chunk_f4 = NP * BS;
const int f4_offset = split_id * chunk_f4;
const float4 *chunk_in =
reinterpret_cast<const float4 *>(in + row * N) + f4_offset;
float4 *chunk_out = reinterpret_cast<float4 *>(out + row * N) + f4_offset;
#pragma unroll
for (int i = 0; i < NP; i++) {
float4 v = __ldg(chunk_in + tid + i * BS);
v.x = __expf(v.x - global_max) * invSum;
v.y = __expf(v.y - global_max) * invSum;
v.z = __expf(v.z - global_max) * invSum;
v.w = __expf(v.w - global_max) * invSum;
chunk_out[tid + i * BS] = v;
}
}
this is essentially what tiling is. but a little different as we want to prevent that intermediate buffer that tiles usually have. we can't have buffers otherwise we would have the same problem we've been facing until now. so the solution is:
- Kernel 1 (stats):
- Each block loads its chunk into registers (1 DRAM read)
- Computes local (max, sum) via online reduction
- Writes partial max/sum to a tiny scratch buffer (2 floats per block)
- Writes exp(x_i - block_max) to output (1 DRAM write) (not yet divided by global_sum; uses block-local max, not global max)
Traffic: 1N read + tiny scratch.
once we have the local maxes across the whole row, we normalize:
- Kernel 2 (normalize):
- One block per row. Merges all SPLITS partial (max, sum) pairs → gets the true global_max and global_sum
- For each split's chunk: computes correction = exp(block_max - global_max) / global_sum
- Reads output, multiplies by correction, writes back (1 read + 1 write)
Traffic: 1N read + 1N write.
There's no way to synchronize across blocks within a single kernel launch in standard CUDA (no global barrier mid-kernel). So the kernel boundary acts as the synchronization point: by the time kernel 2 is launched, all partial stats are committed to global memory and visible.
That's the only reason we have 2 kernels here. If we could barrier across all blocks mid-kernel, we'd merge them into one.
This multi-block approach trades a clean extra pass (kernel 2) for guaranteed no-spill execution in kernel 1. So even though this is a 3N minimum kinda kernel, it performa better as we bypass the issues of the previous 2 pass like spill.
the first kernel essentially computes a local max in its own tile. (it's weird that this is the trick we used in the warp reduction kernel, which was the first optimization... that same kind of idea ended up giving us a better performance than industry standard benchamrks.. crazy)
I should add as a caveat that to blow past the performance I've used intrinsics like __expf and __frcp_rn that will reduce the precision in favor is getting shit down quickly. This doesnt affect softmax as much as it's normalizing across the whole row always, but one must be careful in using these intrinsics without understanding the tradeoff.
I was reading CCCL by nvidia and it turns out they benchmark directly with cmakelists. will have to remember to do that from the next time. wnder, if they bother with triton kernels? or maybe the better universal benchmark would be in cutedsl, that would make more sense.
anyways, thanks for sticking with me if anyone made it this far. I'm still very new to writing blogs so there might be a lot of extra jibber jabber but these are worklogs and my stream of consciousness, so it's what it is.